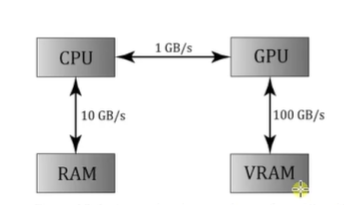
GPU와 VRAM 사이 데이터 전송 속도는 CPU 와 RAM 사이 데이터 전송속도보다 훨씬 빠르다.
그리고 CPU와 GPU간 데이터 전송 속도가 가장 느리다.

GPU와 VRAM이 데이터를 주고 받을 때 CPU보다 훨씬 빠른 이유는 무엇일까? CPU는 RAM과 데이터를 주고 받을 때
L1,L2,L3 캐시에서 데이터를 찾는다. L1에 데이터가 없다면 L2, 그 다음은 L3, 그다음은 RAM까지 내려간다.
그리고 코어가 많으면 멀티스레딩을 할 때 훨씬 더 빨리 계산을 할 수 있다. 코어가 많을 수록 스레드를 많이 띄워서
계산할 수 있기 때문인다. GPU는 최근 것은 코어가 4000개가 넘을 정도로 많은 것에 비해 CPU는 열몇개 남짓이다.
그래서 속도가 차이날 수 밖에 없다. 하지만 CPU는 코어가 전부 다른 작업을 할 수 있다. GPU는 여러개의 코어들이
동일한 프로그램을 실행하는데 적합하게 되어있다.
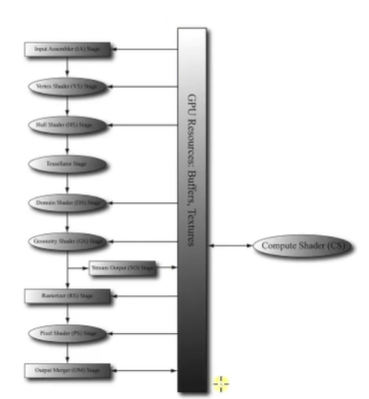
그렇다면 컴퓨트 쉐이더는 무엇일까? 기존 렌더링 파이프라인과 관계되어 있지 않고 컴퓨트 쉐이더만 구현하면
GPGPU (CPU에서 GPU처럼 계산하는) 연산을 할 수 있다.
sd.BufferUsage = DXGI_USAGE_RENDER_TARGET_OUTPUT |
DXGI_USAGE_UNORDERED_ACCESS; // Compute Shader
백버퍼를 설정할 때 포맷은 16비트FLOAT, BufferUsage에 DXGI_USAGE_UNORDERED_ACCESS를 추가한다. 이것을
추가하면 Compute Shader에서 버퍼를 읽어들이고 출력할 수 있다. 기존에 PS에서 출력할 픽셀의 위치를 정할 수 없었다.
Compute Shader에서는 어느 픽셀을 출력할지 결정할 수 있다.
D3D11_UNORDERED_ACCESS_VIEW_DESC uavDesc;
ZeroMemory(&uavDesc, sizeof(uavDesc));
uavDesc.Format = desc.Format;
uavDesc.ViewDimension = D3D11_UAV_DIMENSION_TEXTURE2D;
uavDesc.Texture2D.MipSlice = 0;
ThrowIfFailed(m_device->CreateUnorderedAccessView(
backBuffer.Get(), &uavDesc, m_backUAV.GetAddressOf()));
// CS에서 사용할 Consts 버퍼
D3D11Utils::CreateConstBuffer(m_device, m_constsCPU, m_constsGPU);
// CS 만들기
D3D11Utils::CreateComputeShader(m_device, L"Ex1401_CS.hlsl", m_testCS);
Compute Shader을 위한 Unordered Access View (UAV)를 만들어줘야 한다. 그리고 CS에서 사용할 Const 버퍼를 만들고
CreateComputeShader로 CS를 만든다. CreateComputeShader도 다른 쉐이더 만드는 함수와 크게 다르지 않다.
AppBase::SetPipelineState(m_testComputePSO);
m_context->CSSetConstantBuffers(0, 1, m_constsGPU.GetAddressOf());
m_context->CSSetUnorderedAccessViews(0, 1, m_backUAV.GetAddressOf(), NULL);
// TODO: ThreadGroupCount를 쉐이더의 numthreads에 따라 잘 바꿔주기
// TODO: ceil() 사용하는 이유 이해하기
m_context->Dispatch(UINT(ceil(m_screenWidth / 256.0f)), m_screenHeight, 1);
// 컴퓨터 쉐이더가 하던 일을 끝내게 만들고 Resources 해제
AppBase::ComputeShaderBarrier();
Render에서 다른 쉐이더처럼 SetConstantBuffer, SetUAV를 해주고 Dispatch를 한다. 렌더링 파이프라인에서 그릴 때는
DrawIndexed 같은 함수를 사용했는데 CS에서 그 역할을 하는 함수가 Dispatch다.
void AppBase::ComputeShaderBarrier() {
// 예제들에서 최대 사용하는 SRV, UAV 갯수가 6개
ID3D11ShaderResourceView *nullSRV[6] = {
0,
};
m_context->CSSetShaderResources(0, 6, nullSRV);
ID3D11UnorderedAccessView *nullUAV[6] = {
0,
};
m_context->CSSetUnorderedAccessViews(0, 6, nullUAV, NULL);
}
ComputeShaderBarrier에서는 SRV, UAV를 모두 null로 설정한다. 스레드에게 다른 작업을 할거니까 너는 그만 쓰라고
말해주는 것이다. GPU에서는 계속 작업중일 수 있는데, 그러면 작업이 끝날 때까지 기다린다. 앞에서 Dispatch를 통해서
Compute Shader에게 일을 시킨게 다 끝날때까지 기다린다는 의미의 함수다.
'그래픽스' 카테고리의 다른 글
| [그래픽스] Vertex Buffer을 생성할 때 Usage를 Dynamic으로 하면 터지는 이유 (0) | 2023.08.04 |
|---|---|
| [그래픽스] Compute Shader 써보기 (0) | 2023.07.24 |
| [그래픽스] 부드러운 그림자 - PCSS (0) | 2023.07.23 |
| [그래픽스] 부드러운 그림자 - PCF (0) | 2023.07.23 |
| [그래픽스] 그림자 (0) | 2023.07.23 |

